Transformer由论文《Attention is All You Need》提出,Tensorflow的代码可以从 GitHub 上的 Tensor2Tensor 仓库获取。
1. Transformer 的结构
Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。每一个encoder和decoder的内部结构如下图:
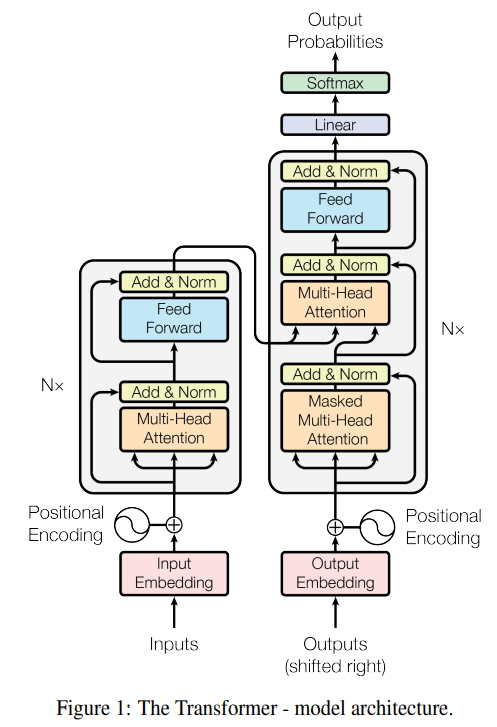
encoder,包含两层,一个self-attention层和一个前馈神经网络,self-attention能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。
decoder也包含encoder提到的两层网络,但是在这两层中间还有一层attention层,帮助当前节点获取到当前需要关注的重点内容。
Transformer 的工作流程大体如下:
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
第二步:将得到的单词表示向量矩阵传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C。
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
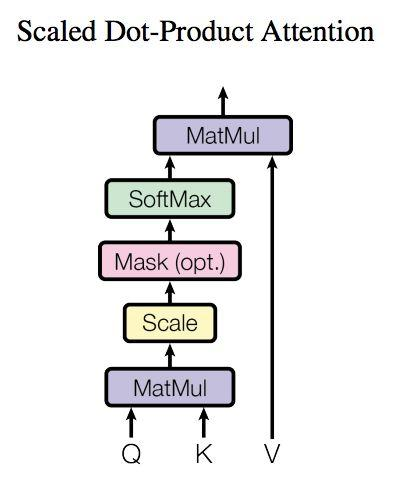
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。