CPU 和 GPU 的主要区别在于它们的设计目标。CPU 的设计初衷是执行顺序指令。一直以来,为提高顺序执行性能,CPU 设计中引入了许多功能。其重点在于减少指令执行时延,使CPU 能够尽可能快地执行一系列指令。
而 GPU 则专为并行和高吞吐量而设计,,但这种设计导致了中等至高程度的指令时延。当需要进行数百万甚至数十亿次这样的计算时,由于 GPU 具有强大的大规模并行能力,它将比 CPU 更快地完成这些计算任务。
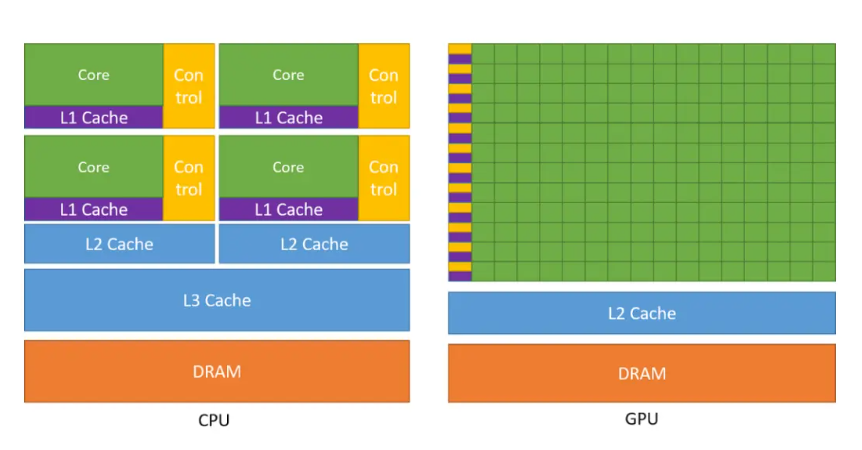
CPU 在芯片上有大量的内存和缓存以及控制单元,但只有少量的ALU和寄存器。GPU缓存较少,但ALU较多,GPU 拥有大量线程和强大的计算能力,即使单个指令具有高延迟,GPU 也会有效地调度线程运行,以便它们在任意时间点都能利用计算能力。
SM
GPU 的计算架构GPU 由一系列流式多处理器(SM)组成,其中每个 SM 又由多个流式处理器、核心或线程组成。
每个 SM 都拥有一定数量的片上内存(on-chip memory),通常称为共享内存或临时存储器,这些共享内存被所有的核心所共享。同样,SM 上的控制单元资源也被所有的核心所共享。此外,每个 SM 都配备了基于硬件的线程调度器,用于执行线程。除此之外,每个 SM 还配备了几个功能单元或其他加速计算单元,例如张量核心(tensor core)。
GPU的内存架构
- 寄存器:让我们从寄存器开始。GPU 中的每个 SM 都拥有大量寄存器。这些寄存器在核心之间共享,并根据线程需求动态分配。在执行过程中,每个线程都被分配了私有寄存器,其他线程无法读取或写入这些寄存器。
- 常量缓存:接下来是芯片上的常量缓存。这些缓存用于缓存 SM 上执行的代码中使用的常量数据。为利用这些缓存,程序员需要在代码中明确将对象声明为常量,以便 GPU 可以将其缓存并保存在常量缓存中。
- 共享内存:每个 SM 还拥有一块共享内存或临时内存,它是一种小型、快速且低时延的片上可编程 SRAM 内存,供运行在 SM 上的线程块共享使用。共享内存的设计思路是,如果多个线程需要处理相同的数据,只需要其中一个线程从全局内存(global memory)加载,而其他线程将共享这一数据。合理使用共享内存可以减少从全局内存加载重复数据的操作,并提高内核执行性能。共享内存还可以用作线程块(block)内的线程之间的同步机制。
- L1 缓存:每个 SM 还拥有一个 L1 缓存,它可以缓存从 L2 缓存中频繁访问的数据。
- L2 缓存:所有 SM 都共享一个 L2 缓存,它用于缓存全局内存中被频繁访问的数据,以降低时延。需要注意的是,SM 并不知道它是从 L1 还是 L2 中获取数据。SM 从全局内存中获取数据,这类似于 CPU 中 L1/L2/L3 缓存的工作方式。
- 全局内存:GPU 还拥有一个片外全局内存,它是一种容量大且带宽高的动态随机存取存储器(DRAM)。由于与 SM 相距较远,全局内存的时延相当高。
GPU kernel
GPU 上执行 kernel,我们需要启用多个线程,这些线程总体上被称为一个网格(grid),但网格还具有更多的结构。一个网格由一个或多个线程块(有时简称为块)组成,而每个线程块又由一个或多个线程组成。线程块和线程的数量取决于数据的大小和我们所需的并行度。例如,在向量相加的示例中,如果我们要对 256 维的向量进行相加运算,那么可以配置一个包含 256 个线程的单个线程块,这样每个线程就可以处理向量的一个元素。
由于 SM 的数量有限,而大型 kernel 可能包含大量线程块,因此并非所有线程块都可以立即分配执行。GPU 会维护一个待分配和执行的线程块列表,当有任何一个线程块执行完成时,GPU 会从该列表中选择一个线程块执行。
线程还会进一步划分为大小为 32 的组(称为 warp),并一起分配到一个称为处理块(processing block)的核心集合上进行执行。SM 通过获取并向所有线程发出相同的指令,以同时执行 warp 中的所有线程。然后这些线程将在数据的不同部分,同时执行该指令。
由于多个线程同时执行相同的指令,这种 warp 的执行模型也称为单指令多线程 (SIMT)。这类似于 CPU 中的单指令多数据(SIMD)指令。
warp
即使 SM 内的所有处理块(核心组)都在处理 warp,但在任何给定时刻,只有其中少数块正在积极执行指令。因为 SM 中可用的执行单元数量是有限的。有些指令的执行时间较长,这会导致 warp 需要等待指令结果。在这种情况下,SM 会将处于等待状态的 warp 休眠,并执行另一个不需要等待任何结果的 warp。这使得 GPU 能够最大限度地利用所有可用计算资源,并提高吞吐量。
零计算开销调度:由于每个 warp 中的每个线程都有自己的一组寄存器,因此 SM从执行一个 warp 切换到另一个 warp 时没有额外计算开销。