uber的Horovod 发表在 Horovod: fast and easy distributed deeplearninginTensorFlow。
horovod 提供的各种框架的支持可以让 horovod 比较好的在各个框架的基础上使用,他支持 tensorflow/keras/mxnet/pytorch,MPI 的实现也有很多,比如 OpenMPI 还有 Nvidia 的 NCCL,还有 facebook 的 gloo,他们都实现了一种并行计算的通信和计算方式。
用法
horovod追求以尽可能小的代码侵入性。
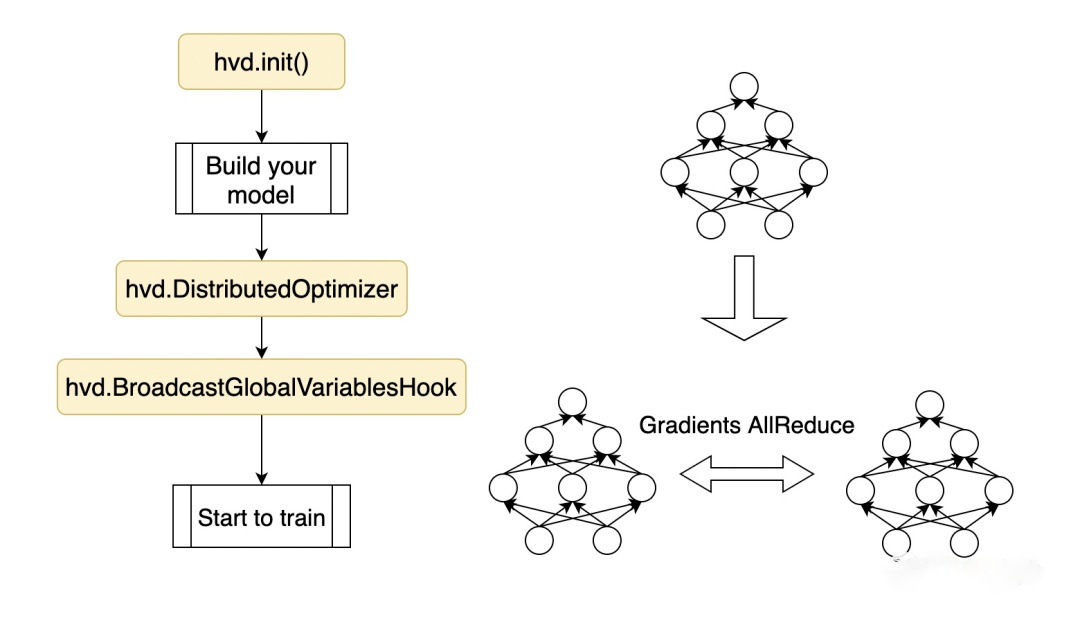
在用户已经构建的代码上,只需要插入三段很短的代码即可,Horovod易用性甚好。因为只要用户的代码没问题,Horovod这三段植入不会让你的程序break。
-
hvd.init()
-
创建horovod的优化器,即DistributedOptimizer,将旧的优化器封装起来
-
创建horovod的初始化hook,即BroadcastGlobalVariablesHook,将master的初始化值广播给其他worker
hvd.init()这个函数。用户的这一句话,启动了Horovod的所有轮询进程及资源管理过程,下图描述了hvd.init()的宏观调用栈,核心就是background thread上启动的BackgroundThreadLoop()函数,它将常驻在进程中并不断轮询,直到程序完全结束。
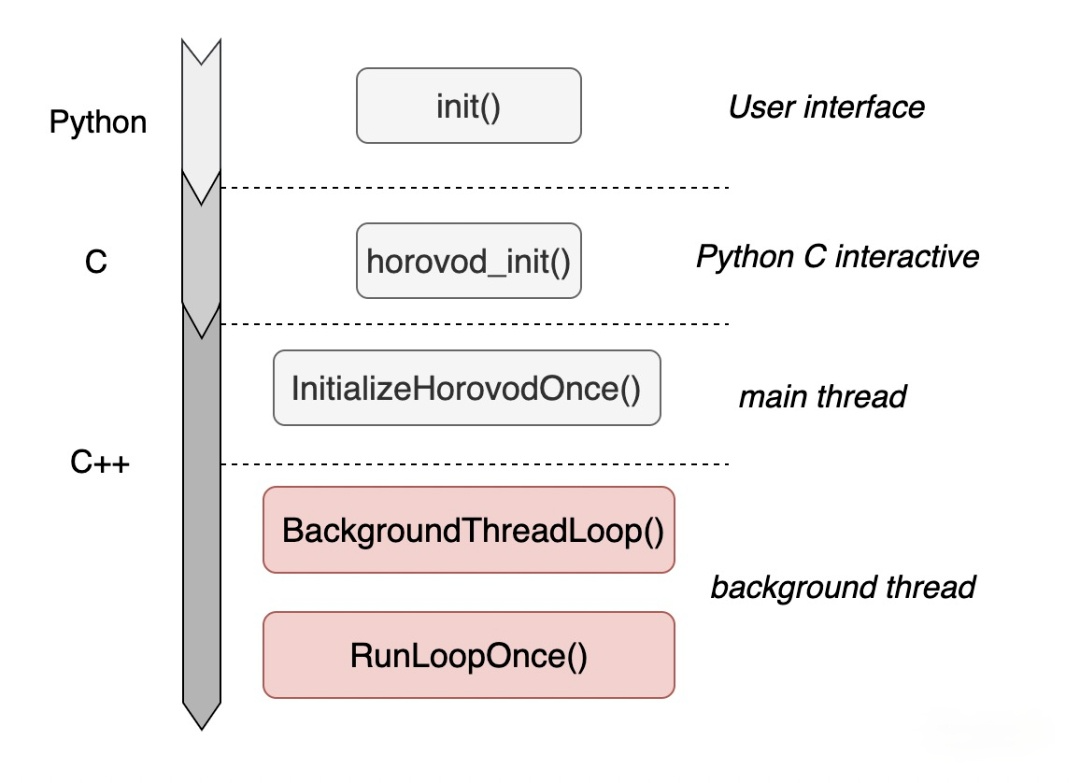
Horovod借助BackgroundThreadLoop()函数对RunLoopOnce()函数做无限循环调用。
若某份gradients已经产生,何时做AllReduce才能不死锁?显然,不可能见到一份gradients就马上做,因为这有概率会陷入死锁。正确答案应该是:
“当该份gradients在所有的worker上均已经产出时,才能统一发动AllReduce”
此时,不会有worker因为在等待其他某个worker没有产出该份gradients而进入无限等待的情况。那么就需要有一种机制,能够观察每份gradients在每个worker上的产出情况。
实际上,上述过程其实就是Horovod的做法。BackgroundThreadLoop为什么一直要轮询?就是要不断地做通知,计数等管理工作。因此,rank 0又被称为——Coordinator。等到真正需要做AllReduce时,RunLoopOnce会调用PerformOperation发动通信过程。