华为诺亚方舟提出了SFCTR ScaleFreeCTR: a MixCache-based distributed training system for CTR,scalefree 可能是因为数据规模对训练吞吐没有影响,后面实验部分有具体的数据。
一、动机与主要创新
现有的分布式CTR训练框架使用CPU内存来保存和更新参数,使用gpu 进行前向和反向计算(也有用CPU的),会有两个瓶颈
-
CPU 和 gpu 之间的pull 和 push 操作有一定的延迟
-
cpu 进行参数的同步和更新比较慢
分布式训练的关键在于
- 关键在于减少host_gpu之间的延迟
- 减少host-gpu 及gpu之间的数据传输量也很重要
推荐中的参数有两个特点:
- 实际 working parameters 比较少,sparse 参数和 MLP参数都很少
- sparse 特征符合幂律分布,小部分特征被高频访问
根据两个特点,可以有两个方法
- 使用缓存机制减少 host-gpu 延迟
- 通过重组batch数据来减少参数传输量(unique?)
由此提出了 SFCTR:
在CPU中通过 虚拟sparse id op 来减少host-gpu 和gpu-gpu 的数据传输量,使用 mixcache 实验特征预取来减少传输延迟,使用3级pipeline 来减少整体训练时长。
系统将会在MindSpore 上开源,现在看似乎还没有开源。
二、相关工作
(一)论文介绍的跟SFCTR无关,但挺有用的经验知识
为了提高训练效率,有两种通用的做法:
- 增量学习(batch训练的补充,用最近的数据更新模型)
- 分布式训练(使用额外的训练资源)
CTR模型稀疏部分参数量太大,所以不能使用reduce 数据并行,大多数考虑用了模型并行。
模型并行解决方案ps 架构的局限性:
Ps server 保存并同步参数,worker执行前向和反向计算,
- worker pull and push from ps
- Ps 从worker接收梯度之后进行同步
分布式训练包括两个阶段:计算和参数同步。
百度的综述 Distributed Hierarchical GPU Parameter Server for Massive Scale Deep Learning Ads Systems 介绍了三种同步模式:
- BSP(bulk sync parallel),严格对所有worker的更新进行同步
- SSP(stale sync parallel),对快worker 进行同步
- ASP(async parallel), 不同步gradient
后两种方式虽然提升了训练效率,但是降低了模型性能。SFCTR 使用的是BSP,XDL使用的是ASP。
三、SFCTR 架构
SFCTR 由三部分构成
- Data-Loader, 提出虚拟sparse id op 来减少batch中重复的特征emb(unique?)
- Host-Manager, 使用混合缓存策略来减少host-gpu延迟,MixCache 的管理器部分在 CPU 的内存中,MixCache 的缓冲区在 GPU 的 HBM 中
- GPU-WORKER
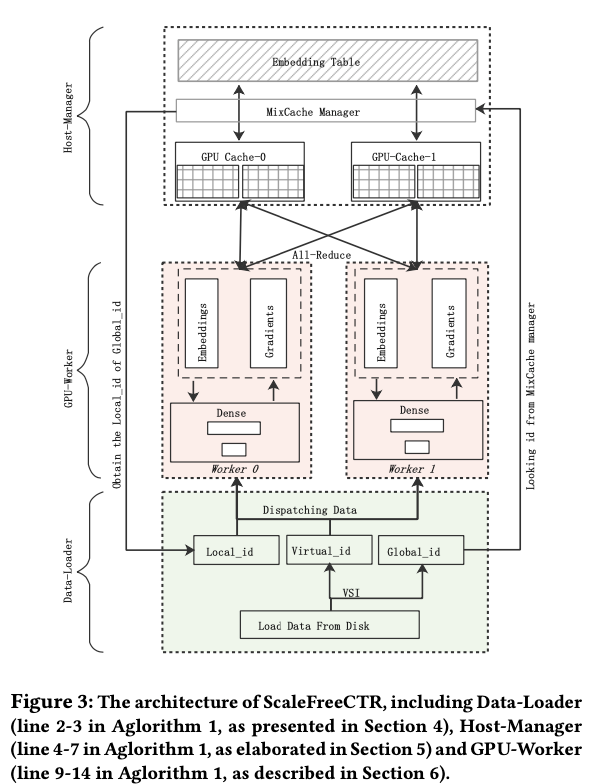
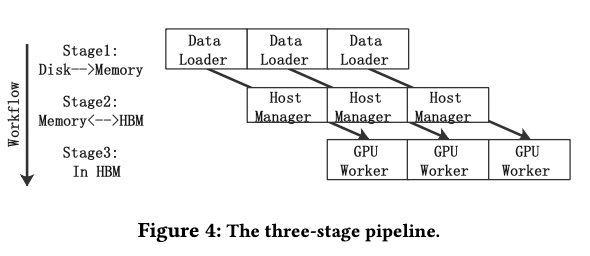
3级pipeline
把 Data-Loader,Host-Manager 和gpu worker 中,三阶段资源不同 Disk, CPU and GPU在三个不同的线程里完成
(1)data loader
sparse id op 来减少batch中重复的特征emb,就是xdl中的unique。减少host-gpu 和gpu-gpu 的数据传输量。
(2)HOST-MANAGER
MixCache用来减少延迟,在每个GPU的HBM 上申请一个cache buffer,使用modulo 哈希方法对 working parameters 进行分组,放在不同的GPU 上,embedding参数在data loader执行完VSI op 之后检查哪些参数 gpu 上没有就把那些参数传输到gpu 上。
当cache满了之后,满足两种情况的emb 会回传到host。
- 参数完成了更新
- 下个batch不需要这个参数
(3)GPU-WORKER
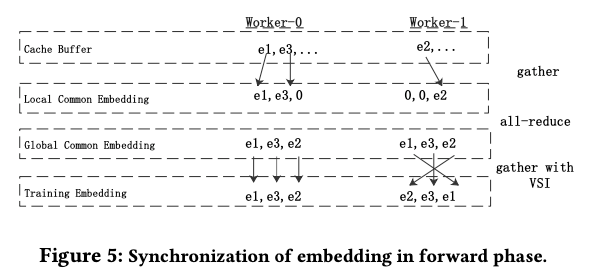
不同的GPU保存了不同的参数,所以前向和反向的时候都需要同步。
前向传播,每个worekr从其它worker拿到batch所需要的参数,使用all-reduce 通信方式,一个gpu只需要跟另外两个gpu通信两次,首先通过gather_cache ,从cache buffer 中获得local common emb, 因为global_id 顺序一致,所以可以做all_reduce同步, 然后通过all_reduce 或者 global common emb,最后通过vis 算出来自己worker需要执行的batch emb
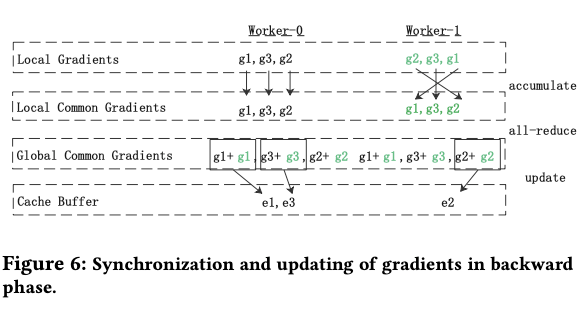
梯度更新
四、SFCTR 执行流程
执行流程

-
2-3行是 data loader 部分,有个虚拟Sparse Id OP,对batch Sparse ID 去重后形成 global_id,对于batch 中每个实例有个virtual_id,可以找到其对应的global_id ,跟XDL 的unique 操作很像。使用global_id, 各个gpu在同步的时候数据量就会少很多。
-
4-7行是 Host-Manager 部分,负责在主存中报错embedding参数(存得下吗?),使用mixcache把working parameters 放到 gpu 的cache buffer中。mixcache 还更新gpu cache buffer, 检查下一个batch需要哪些embedding ,预测哪些embedding未来一段时间不需要,在buffer满的时候进行pull, 发送数据到gpu,并对每个特征在gpu设置一个local_id (?)
-
9-15行是GPU部分,包括embedding查表,前向反向和参数更新
host 和 gpu 是生产者与消费者模式
五、一些对我们有用的实验:
(1)环境
GPU 集群使用 InfiniBand 连接,4台GPU服务器通过100Gb RDMA提速
Intel Xeon Gold-5118 CPUs with 18 cores (36 threads), 8 Tesla V100 GPUs with 32 GB HBM,1GB内存。GPU之间PCI连接
使用 Criteo-TB 数据库,使用filter构造10GB和100GB两个数据集,因为包括了优化器的信息,33×4B×80=10GB,所以实际parameter table是embedding table的3倍,所以实际上是 30GB和300GB的模型参数。
使用 DeepFM 模型,与 hugectr与ps mxnet对比
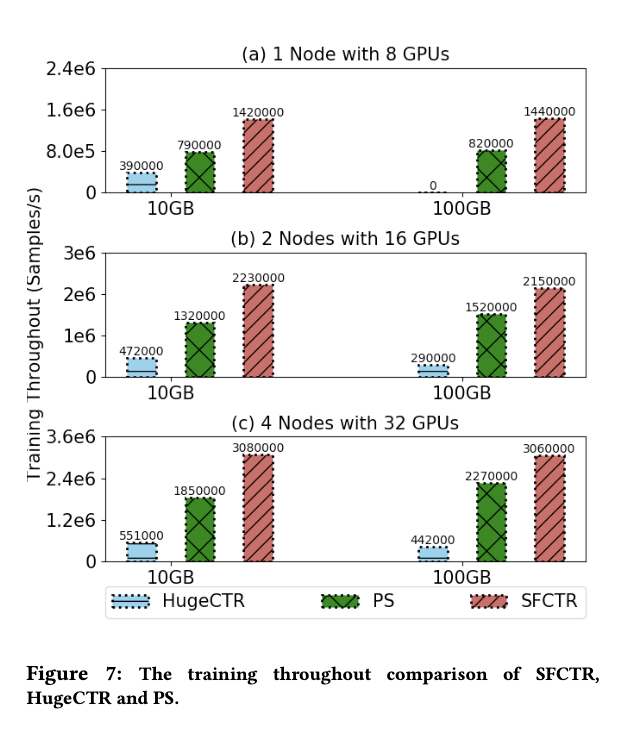
(2)框架对比实验
基于VSI OP,混合缓存机制,和三级pipeline,在10GB数据上SFCTR 在4机32卡上的吞吐量是psmxnet的1.6倍,hugectr的5.6倍,100GB 数据上是1.3倍和6.9倍
如果GPU卡只有8个,hugectr在100GB数据上根本无法训练
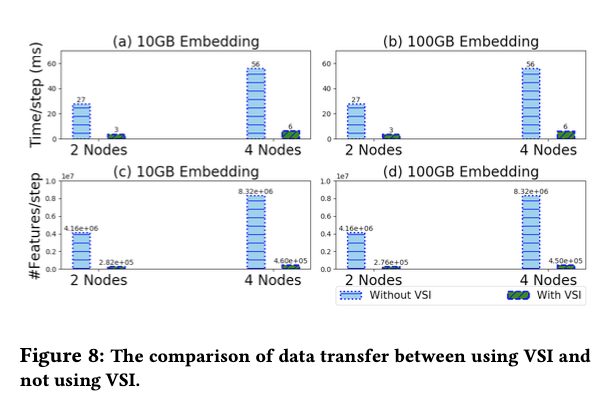
(3)vsi op
Host-gpu 数据传输量减少 94% ,g pu-gpu数据量减少88%
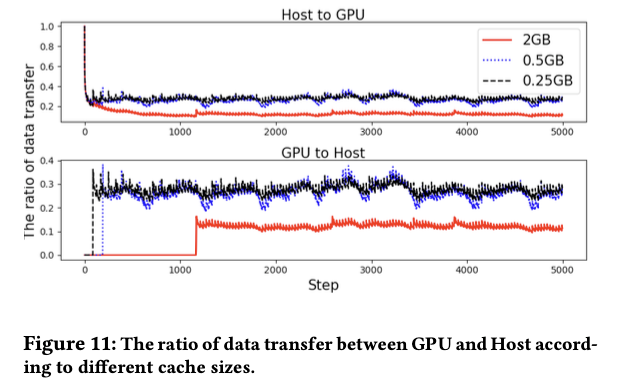
(4)mixcache
Cache 大小对传数据的影响
2GB的cache可以把数据传输推迟到1000步之后
如果cache 大小比较大,batch中要传输的数据的比例就会小,因为可以存更多高频特征
12%(2GB), 27%(0.5GB) and 29%(0.25GB)
(5)3级pipeline
GPU-Worker 训练时间在pipeline中占比最高
一个节点跑100GB数据,使用pipeline需要 75 s,不用pipeline就需要150s
六、总结与思考
文章写的通俗易懂,很有条理,related worker 也总结了很多训练的经验,工作很有实用性。
作者提到未来的工作有两个方向
- 提升通信效率,(使用all2all)
- 调查提升收敛速度的方法
思考借鉴意义
-
SFCTR相当于把图完全放在GPU中执行,没有进行图的分隔,所以实现起来更容易一些。CPU只是一个ps的存储和更新后落盘以及dataloader
-
CPU内存1T,而实验中的数据最大的为300GB,所以可以放在CPU内存中,其实我们的模型大小似乎也在几百GB,如果可以放在worker内存中,就没有必要单独弄一个ps server;
如果模型超过1T,也可以融合AIBox的做法,使用SSD做cpu mem的缓存 -
pipeline 和 vsiop 其实 XDL 都有,只缺了缓存机制,但XDL如果不动ps这一块,参数的更新其实是在ps 上完成的,所以 ps 的 push 也会继续有延迟,参数预取只能解决pull 的问题,
-
但如果都在本地更新,那不同worker之间参数同步就会比较麻烦,所以缓存预取、更新后缓存失效再回传的机制必然依赖多机间 RDMA 单机allreduce 同步通信技术,ps存在的意义不大