AIBox 是百度提出的训练框架,论文 AIBox: CTR Prediction Model Training on a Single Node 进行了相关介绍。
一、AIBox 的技术创新及优势
创新点与动机:
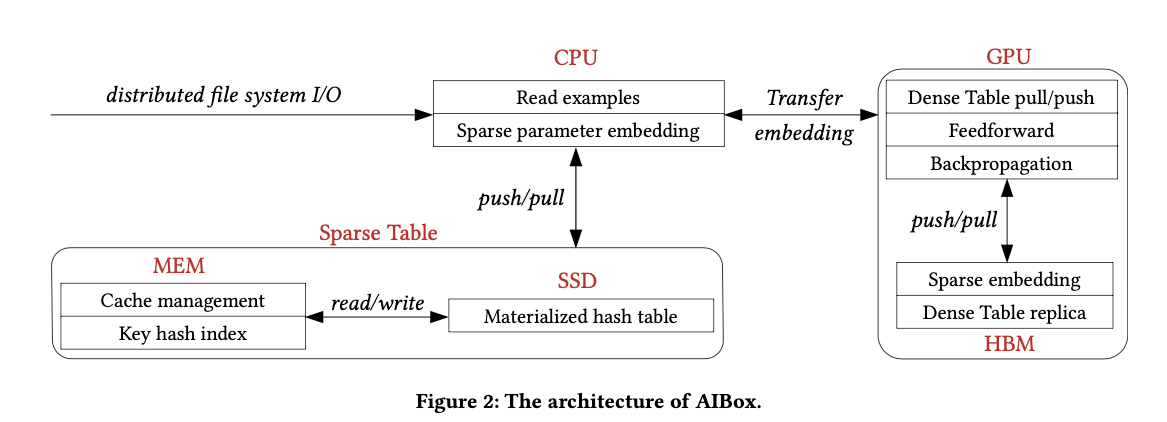
AIBox 的核心想法就是想在一台机器上用GPU加速训练,但是参数实在太大了,所以就把计算密集的模型运算部分(joint learning)放在GPU完成,把取embedding 部分放在cpu部分完成(embedding learning),这就是AiBox 的第一个创新:把网络切分为两部分。
但即便主存用了1TB 的内存,embedding 还是太大了,10^12 个key,每个key 的 weight 即使用8个字节存,key用8个字节存,也需要1.6TB , 所以论文提出了第二个创新:把embedding 存在SSD上,同时为了降低延迟和减少写操作对ssd寿命的影响,建立了二级缓存机制。
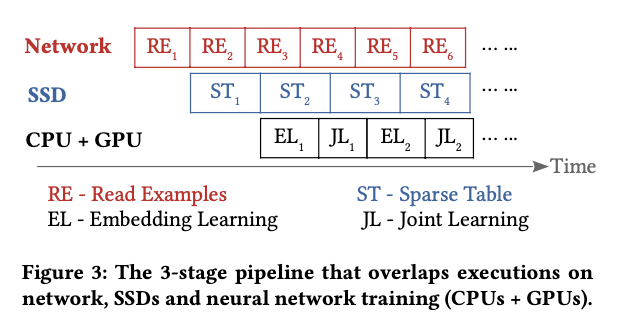
为了提高速度,AIBOX使用了流水线,把从hdfs 读数据(socket IO),从SSD查Embedding (SSD io) 和 cpu+gpu 计算组成3阶段的 pipeline
优势:
AIBOX不存在像分布式系统普遍存在的网络通信开销问题,然后在系统稳定性方面AIBOX与具有数千台机器的分布式集群相比更加稳定不会轻易宕机,而且在同步开销方面AIBOX只是涉及到一些内存锁和GPU片之间的少量通信。
二、关于网络结构切分
the first module focuses on the embedding learning with high-dimensional & sparse features and the second module is for joint learning with dense features resulted from the first module.
The embedding learning is processed on CPUs to help learn low dimensional dense embedding representations.
By transferring the learned embedding vectors from CPUs to GPUs, the computation-intensive joint learning module can make full use of the powerful GPUs for CTR prediction.
CPU 部分把数据从稀疏特征转化成 embedding (embedding learning),然后把embedding 传到 GPU,GPU进行一轮训练 (joint learning)
论文这部分讲了一些网络的设计细节,但这块感觉跟 AIBox本身没什么关系,论文写到:
把第一隐含层和最后一层隐含层的结果合并起来,第一层包含了low-level 的与输入信息最相关的feature,最后一层包含了high-level 的最抽象和有用的信息。这样会得到更准确的CTR预估结果。
训练两阶段(cpu+gpu),梯度更新也是两阶段(gpu+cpu)。
三、AIBox 架构划分
架构:
分为三部分:CPU、GPU和 sparse table buff
-
cpu模块:协调调度和embedding学习
从hdfs读数据(一个pass),向Sparse Table模块查embedding,然后发给GPU
拿到gpu传来的梯度,更新sparse table
定期save ckpt 到 hdfs -
sparse table:把10^12 的离散特征的数据存储到ssd上的kv系统里
内存中的key hash 索引存了特征到文件的映射关系,
in-memory cache strategy 构造cache 和 buffer 来减少延迟 -
gpu模块:联合学习
cpu传来的 embedding 被放入 HBMs 中,然后被fed 给 dense 联合学习网络
emb通过pci-e总线进行传输
一个CUDA stream进行数据传输,另一个cuda stream 进行学习计算
HBMs如同片上ps一样工作,
每个pass 在每个gpu 上计算新的参数,各gpu通过NVLink进行同步
3阶段流水线:network, SSDs and CPUs + GPUs
四、sparseTable 架构
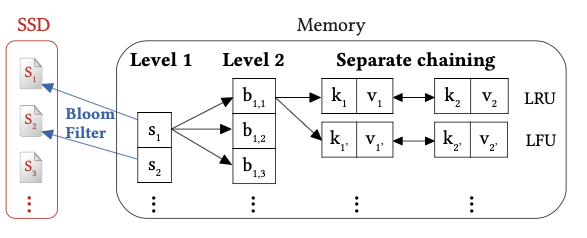
由两部分构成:key hash index and bi-level cache management
(一)key hash index
Key Hash Index 存的是 10^12 个 feature key 到 ssd 文件的映射关系,直接每个key 存一个文件需要1.6TB大小的内存,放不下。
通过对key 取模进行分组建立 group 与 file 的对应关系,放在内存中。
group(key) → key mod 1012/m. We set m = ⌊BLOCK/(8 + sizeof(value))⌋,其中Block 是每次从ssd取数据的最小单元。
hash函数可以通过预训练一个模型来最大化feature 共现,把共现的feature 分到同样的桶里面。
(二)二级缓存机制
ssd 的延迟是内存的1000倍,ssd是微秒级别延迟,内存是纳秒级别延迟
在一个 pass of mini batch 中只有1%的参数会被用到,所以我们可以用in-memory cache 来存储高频访问的hot parameters
SSD有物理性能限制:每个存储单元只能被写入(擦除)数千次,cache机制可以作为参数缓存,来减少更新参数对SSD使用寿命的影响
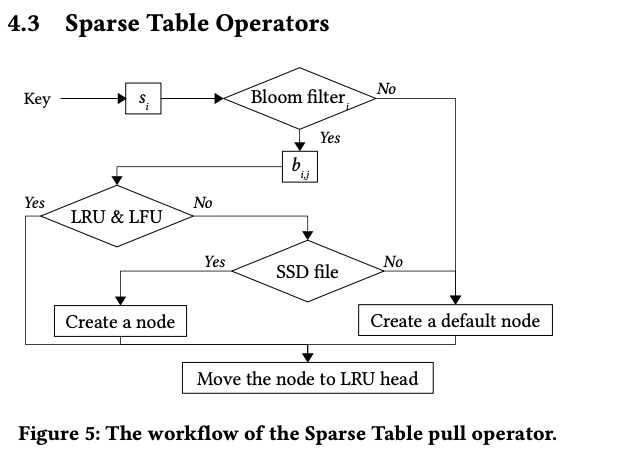
使用两个分离的链表进行拉链来提升探测性能。对每个ssd文件使用Bloom filter来减少不必要的读取。
第一级缓存
使用 si =hash1(g_id) 来算出一个 cache slot 槽,对应一个ssd 文件,对于参数并未进行真正初始化,而是在第一次访问到参数的时候,先用 bloom filter 探测key 是否在 slot 集合里,如果不在就不用读取这个文件,而是直接使用默认值,以此来减少不必要的ssd读取。
二级缓存
hash2(g_id, bucket)
对 一级的槽进行分桶bucket,来使得拉的链比较短。bucket 参数通过调节可以权衡空间和探测效率
两条拉链
- LRU 链用于保存最近访问过的key,以此来减少探测次数
- LFU链按访问频次来保存key,用于缓存管理,只有当LFU满了需要删除低频key时,相应的数据才会写回到ssd上面
由于经常有链条中的节点进行增删,所以使用线程池以Slab memory allocation mechanism机制 进行管理。
文件管理系统
batch产生的小文件对于先有的文件系统有很大的压力,把许多小文件组成一个组来创建较少的文件。小文件的名字由大文件的名字加上offset构成,保存在第一级cache slot 中
监控文件系统的大小,合并访问量少的小问题,当model_size 达到最大冗余度的时候删掉访问少的文件,MAX_REPLICATION=SSD capacity ∗ (85% + overprovisioning)/model size
五、实验部分
实验
AIBox 8 个GPU, 服务器级别的cpu, 1T 内存,Raid 0 nvme ssd
MPI集群方式用75个计算节点
-
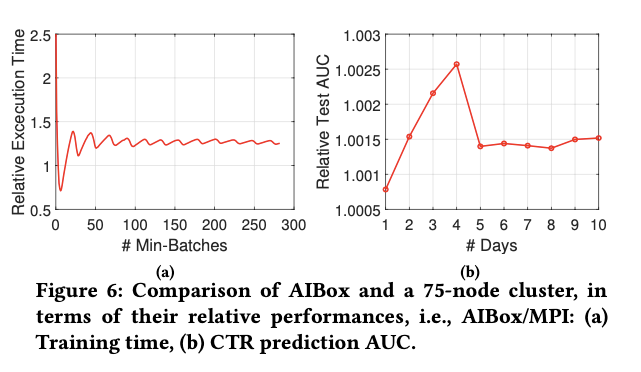
AIBox 的硬件和维护费用比集群训练方式少 10%,执行时间多25%
-
AIBox 的auc 比集群方式稍好,可能是因为AIBox 这种单节点的方式,同步参数频率更高
六、总结与一些细节问题:
论文介绍了 AIBox 架构的一些细节方面,借助一系列系统设计方案如缓存机制来解决问题,通过这些并不是很fashion的技术合并,论文实现了集中式训练的技术突破,这种通过技术积累然后撬动难题的解决问题的方式值得我们学习。
但是还有一些细节没有讲清楚:
-
AIBox 有几个worker 进行工作,他们是数据并行,还是使用同样的数据进行训练(文中提到AIBox 会在每个pass of mini batch 进行同步,所以应该不是一个worker 在参与训练)
-
AIBox 使用集中的训练方式,那如果这台机器挂掉,是不是根本没有办法进行恢复,只能另找一个机器从 ckpt 训练
-
文章没有介绍使用的具体计算引擎 (怀疑跟 horovod 接近)
-
同样文章没有介绍参数同步的细节,没有相关 all_reduce 的介绍(可以是使用了一个开源的框架,而这部分论文没有进行改进,所以没有做深入介绍)
-
文章开头提到使用 in-HBM ps 来减少数据传输,但是后面没有详细进行介绍
总体上感觉这篇论文实用性强,但是细节介绍得不多